PySensMCDA - Illustrative examples
Note: this notebook was created for the purpose of providing an instruction of decision problem sensitivity analysis. For in-depth presentation of graphs submodule see graphs_examples.ipynb
[1]:
## Necessary imports for the notebook to work
from pysensmcda import alternative, criteria, compromise, graphs, probabilistic, ranking, calculate_preference
import numpy as np
import matplotlib.pyplot as plt
[2]:
## Additional imports and function for output formatting
from sympy import Matrix
from IPython.display import display, Markdown
from examples_pretty_print import *
Table of contents:
Alternative submodule:
Discrete modification
Percentage modification
Range modification
Alternative removal
General
Criteria submodule:
Random distribution - weights generation
Percentage modification
Range modification
Weights scenarios
Cirteria identification
Criteria removal
Probabilistic submodule:
Monte carlo weights generation
Perturbated matrix
Perturbated weights
Ranking submodule:
Ranking alteration
Demotion
Promotion
Fuzzy ranking
Compromise submodule:
General
Half-quadratic compromise additional informations
ICRA
Further use
1. Alternative submodule
Note: Alternative submodule includes functions for modification of values along alternatives in decision matrix and alternative removal.
Let us consider following matrix, this matrix will be taken as an initial matrix for further function calls
[53]:
matrix = np.array([
[4, 1, 6],
[2, 6, 3],
[9, 5, 7],
])
print('Initial matrix:')
display(Matrix(matrix))
Initial matrix:
1.1. Discrete modification
For each criterion we can define discrete values that will be set as a value. All possible combinations are generated.
[54]:
discrete_values = np.array([[2, 3, 4], [1, 5, 6], [3, 4]], dtype='object')
pretty_print_alternative(alternative.discrete_modification(matrix, discrete_values)[0])
Alternative index: 0
Criteria index: 0
Change: 2
Resulting decision matrix:
The value of alternative 1 in the first criterion was changed for discrete value ‘2’
1.2. Percentage modification
Percentage values can be set as an int to make it the same for all criteria, or by an array to specify value for specific criterion.
[55]:
percentages = 5
# percentages = np.array([3, 2, 3])
pretty_print_alternative(alternative.percentage_modification(matrix, percentages)[0])
Alternative index: 0
Criteria index: 0
Change: -0.01
Resulting decision matrix:
In the case of percentage modification the value of first alternative under first criterion changed by -0.01, which means -1%
1.3. Range modification
Range values should be specified for each criterion (2d-array) or for each value in decision matrix (3d-array).
[56]:
range_values = np.array([[6, 8], [2, 4], [4, 6.5]])
range_modification_results = alternative.range_modification(matrix, range_values)
pretty_print_alternative(range_modification_results[0])
Alternative index: 0
Criteria index: 0
Change: 6.0
Resulting decision matrix:
The range modification modifies values in specified range, if step is not passed, it is set to 1. The value of first alternative, first criterion was set to 6. In the next step it will be set to 7.
[57]:
display(Markdown('##### **Next step**'))
pretty_print_alternative(range_modification_results[1])
Next step
Alternative index: 0
Criteria index: 0
Change: 7.0
Resulting decision matrix:
1.4. Alternative removal
[58]:
pretty_print_alternative_removal(alternative.remove_alternatives(matrix)[0])
Alternative index: 0
Resulting decision matrix:
[59]:
display(Markdown('##### **Next step**'))
pretty_print_alternative_removal(alternative.remove_alternatives(matrix)[1])
Next step
Alternative index: 1
Resulting decision matrix:
1.5. General
All functions provide additional parameters.
Parameter
indexes- provides a way to restrict the use of function to specific criteria. In the case of alternative removal, this parameter specifies indexes of alternatives that should be removedParameter
direction(only percentage function) - specifies direction of the modification for each column in the matrix.Parameter
step(only range and percentage functions) - specifies step of next change
For example:
[60]:
direction = np.array([-1, 1, -1])
percentages = np.array([2, 4, 9])
indexes = np.array([[0, 2], 1], dtype='object')
step = np.array([2, 2, 3])
results = alternative.percentage_modification(matrix, percentages, direction, indexes, step)
display(Markdown('##### **This will provide change for all alternative at first for the first and third criterion from step to percentage value:**'))
pretty_print_alternative(results[0])
display(Markdown('##### **And separately for all alternatives for second criterion:**'))
pretty_print_alternative(results[3])
This will provide change for all alternative at first for the first and third criterion from step to percentage value:
Alternative index: 0
Criteria index: (0, 2)
Change: (-0.02, -0.03)
Resulting decision matrix:
And separately for all alternatives for second criterion:
Alternative index: 0
Criteria index: 1
Change: 0.02
Resulting decision matrix:
2. Criteria submodule
Note: Criteria submodule includes functions for criteria removal and identification and weights generation.
2.1. Random distribution - weights generation
This part of the submodule is solely dedicated to single weights vector generation. For example let us generate vector of four weights (\(n = 4\)).
[61]:
n = 4
Chisquare distribution
df(Number of degrees of freedom)
[62]:
weights = criteria.random_distribution.chisquare_distribution(n, df=1)
pretty_print_weights(np.round(weights, 6))
Resulting weights vector (example):
Laplace distribution:
loc(The position of distribution peak)scale(The exponential decay)
[63]:
weights = criteria.random_distribution.laplace_distribution(n, loc=0, scale=1)
pretty_print_weights(np.round(weights, 6))
Resulting weights vector (example):
Normal distribution:
loc(Mean of the normal distribution)scale(Standard deviation of the normal distribution)
[64]:
weights = criteria.random_distribution.normal_distribution(n, loc=0, scale=1)
pretty_print_weights(np.round(weights, 6))
Resulting weights vector (example):
Random distribution:
No additional parameters
[65]:
weights = criteria.random_distribution.random_distribution(n)
pretty_print_weights(np.round(weights, 6))
Resulting weights vector (example):
Triangular distribution
left(The lower bound of the triangular distribution)mode(The mode of the triangular distribution)right(The upper bound of the triangular distribution)
[66]:
weights = criteria.random_distribution.triangular_distribution(n, left=0, mode=0.5, right=1)
pretty_print_weights(np.round(weights, 6))
Resulting weights vector (example):
Uniform distribution:
low(Lower bound of the uniform distribution)high(Upper bound of the uniform distribution)
[67]:
weights = criteria.random_distribution.uniform_distribution(n, low=0, high=1)
pretty_print_weights(np.round(weights, 6))
Resulting weights vector (example):
2.2. Percentage modification
This function returns all possible modifications to the weights vector. Single weight is modified at one time, however rest of the weights are equally adjusted to provide a vector which sum is 1.
[68]:
weights = np.array([0.3, 0.3, 0.4])
percentage = 5
results = criteria.percentage_modification(weights, percentage)
pretty_print_weights_generation(weights, results[0])
Initial weights vector:
Modified weight index: 0
Modification: -0.01
Resulting weights vector:
Similarly to alternatives modification functions. Percentage modification for weights provides additional parameters: - direction - specifies the direction of the modification for each criterion weight - indexes - specifies indexes of the criteria weights to be modified - step - specifies step size for the percentage change.
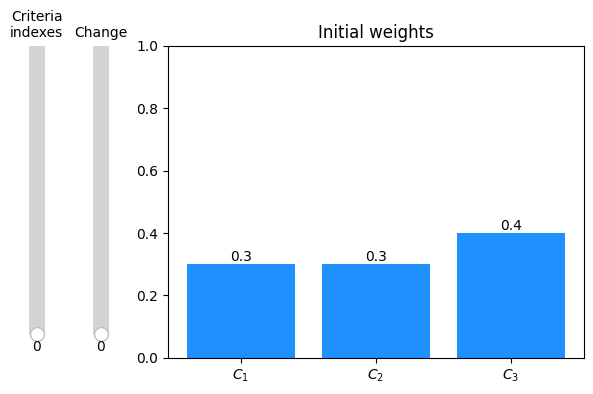
We can further visualize the results.
[13]:
# In the case of using sliders, the reference should be kept, so Python wouldn't GC
ax, criteria_slider, change_slider = graphs.slider_weights_barplot(weights, results, percentage_change=True, annotate_bars=True)
plt.show()
2.3. Range modification
Similarly to percentage modification this function returns all possible modifications to the weights vector. Single weight is modified at one time, however rest of the weights are equally adjusted to provide a vector which sum is 1.
[70]:
weights = np.array([0.3, 0.3, 0.4])
range_values = np.array([[0.25, 0.3], [0.3, 0.35], [0.37, 0.43]])
results = criteria.range_modification(weights, range_values)
pretty_print_weights_generation(weights, results[0])
Initial weights vector:
Modified weight index: 0
Modification: 0.25
Resulting weights vector:
Note: The range modification can be visualized similarly to percentage modification.
Additional parameters: - indexes - specifies indexes of the criteria weights to be modified - step - specifies step size for the percentage change.
2.4. Weights scenarios generation
This function generates all possible combination of weights for specified number of criteria with specified step.
Parallel - it is advised to use parallel version, especially for more than five criteria, default saves results to file
[71]:
scenarios = criteria.generate_weights_scenarios(4, 0.1, 3, return_array=True, save_zeros=False)
pretty_print_weights(scenarios[0])
Resulting weights vector (example):
Sequential - provides additional progress bar, does not utilize temporary files
[72]:
scenarios = criteria.generate_weights_scenarios(4, 0.1, 3, sequential=True, return_array=True, save_zeros=False)
pretty_print_weights(scenarios[0])
100%|██████████| 286/286.0 [00:00<?, ?it/s]
Resulting weights vector (example):
2.5. Criteria removal
This function removes specified criteria from decision matrix, adjusting weights so that the vector sums to 1. If no indexes are specified, all criteria are removed one by one.
[73]:
matrix = np.array([
[1, 2, 3, 4, 4],
[1, 2, 3, 4, 4],
[4, 3, 2, 1, 4]
])
weights = np.array([0.25, 0.25, 0.2, 0.2, 0.1])
print('Initial matrix:')
display(Matrix(matrix))
print('Initial weights:')
display(Matrix(weights).T)
Initial matrix:
Initial weights:
[74]:
results = criteria.remove_criteria(matrix, weights)
display(Markdown(f'##### **Example result (1/{len(results)}):**'))
pretty_print_crit_removal(results[0])
Example result (1/5):
Removed criterion index: 0
Resulting decision matrix:
Resulting weights vector:
2.6. Criteria identification
This method identifies criteria impact on the resulting ranking. It needs multi-criteria decision-making method to calculate preferences internally.
[75]:
matrix = np.array([
[4, 3, 5, 7],
[7, 4, 2, 4],
[9, 5, 7, 3],
[3, 5, 6, 3]
])
criteria_num = matrix.shape[1]
criteria_types = np.array([1, 1, -1, 1])
weights = np.ones(criteria_num)/criteria_num
print('Initial matrix:')
display(Matrix(matrix))
print('Initial weights:')
display(Matrix(weights).T)
print('Initial criteria types:')
display(Matrix(criteria_types).T)
Initial matrix:
Initial weights:
Initial criteria types:
Using defined function - let us define weighted sum method function that returns preference values for alternatives
[76]:
def weighted_sum_method(matrix, weights, types):
# normalize decision matrix with sum normalization
nmatrix = matrix.copy().astype(float)
nmatrix[:, types == 1] = matrix[:, types == 1] / np.sum(matrix[:, types == 1], axis=0)
nmatrix[:, types == -1] = (1 / matrix[:, types == -1]) / np.sum(1 / matrix[:, types == -1], axis=0)
# each row of matrix is multiplied by weights
weighted_matrix = nmatrix * weights
# calculate preference scores
return np.sum(weighted_matrix, axis=1)
[77]:
call_kwargs = {
'matrix': matrix,
'weights': weights,
'types': criteria_types
}
results = criteria.relevance_identification(weighted_sum_method, call_kwargs, ranking_descending=True)
pretty_print_crit_identification(results[0])
Removed criterion index(es): (0,)
Correlation value: 0.52
Distance value: 0.093636
Resulting decision matrix:
The criterion with lowest impact was removed
Using library - example
pymcdm
[78]:
import pymcdm.methods as pm
topsis = pm.TOPSIS()
call_kwargs = {
'matrix': matrix,
'weights': weights,
'types': criteria_types
}
results = criteria.relevance_identification(topsis, call_kwargs, ranking_descending=True)
pretty_print_crit_identification(results[0])
Removed criterion index(es): (0,)
Correlation value: 0.52
Distance value: 0.211707
Resulting decision matrix:
3. Probabilistic submodule
This submodule offers a way to generate \(x\) number of scenarios / samples for introducing noise to decision matrix or weights vector. Additionally it provides a way to generate \(x\) number of samples of random weights vectors.
3.1. Monte carlo
Let us generate 1000 samples of random weights vectors for a problem with 3 criteria.
[14]:
n = 3
modified_weights = probabilistic.monte_carlo_weights(n, num_samples=1000, distribution='normal', params={'loc': 0.5, 'scale': 0.1})
print(modified_weights)
[[0.36291334 0.29830382 0.33878284]
[0.34222087 0.26262817 0.39515096]
[0.30846942 0.35528216 0.33624842]
...
[0.36034416 0.31930061 0.32035523]
[0.29917237 0.4062474 0.29458022]
[0.3324616 0.428281 0.2392574 ]]
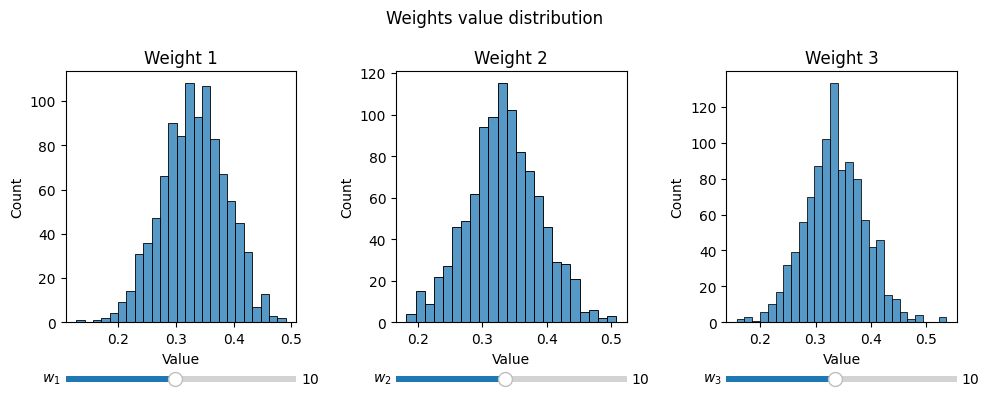
The weights vectors can be further visualized on distribution plot
[15]:
fig, ax = plt.subplots(1, 3, figsize=(10, 4))
for idx in range(modified_weights.shape[1]):
# In the case of using sliders, the reference should be kept, so Python wouldn't GC
_, bins_slider = graphs.hist_dist(modified_weights[: , idx], ax[idx], fig=fig, slider_label=f'$w_{{{idx+1}}}$', kind='hist', xlabel='Value', title=f'Weight {idx+1}')
plt.suptitle('Weights value distribution')
plt.tight_layout(w_pad=1.5)
plt.show()
3.2. Perturbated matrix
[81]:
matrix = np.array([[4, 3, 7],
[1, 9, 6],
[7, 5, 3]])
simulations = 1000
results = probabilistic.perturbed_matrix(matrix, simulations)
print('Initial matrix:')
display(Matrix(matrix))
print(f'Example resulting matrix (1/{len(results)}):')
display(Matrix(results[0]))
Initial matrix:
Example resulting matrix (1/1000):
3.3. Perturbated weights
[82]:
weights = np.array([0.3, 0.4, 0.3])
simulations = 1000
results = probabilistic.perturbed_weights(weights, simulations)
print('Initial weights vector:')
display(Matrix(weights).T)
print(f'Example resulting weights vector (1/{len(results)}):')
display(Matrix(results[0]).T)
Initial weights vector:
Example resulting weights vector (1/1000):
4. Ranking submodule
4.1. Ranking alternation
This function finds smallest possible changes in weights values which will result in different ranking.
[83]:
import pymcdm.methods as pm
weights = np.array([0.4, 0.5, 0.1])
matrix = np.array([
[4, 2, 6],
[7, 3, 2],
[9, 6, 8]
])
types = np.array([-1, 1, -1])
aras = pm.ARAS()
pref = aras(matrix, weights, types)
initial_ranking = aras.rank(pref)
call_kwargs = {
"matrix": matrix,
"weights": weights,
"types": types
}
ranking_descending = True
results = ranking.ranking_alteration(weights, initial_ranking, aras, call_kwargs, ranking_descending)
print('Initial ranking:')
display(Matrix(initial_ranking).T)
print(f'Example result (1/{len(results)}):\n')
print(f'Modified weight index: {results[0][0]}')
print('Resulting weights:')
display(Matrix(results[0][1]).T)
print('Resulting new ranking:')
display(Matrix(results[0][2]).T)
Initial ranking:
Example result (1/3):
Modified weight index: 0
Resulting weights:
Resulting new ranking:
4.2. Demotion
[4]:
import pymcdm.methods as pm
matrix = np.array([
[4, 2, 6],
[7, 3, 2],
[9, 6, 8]
])
weights = np.array([0.4, 0.5, 0.1])
types = np.array([-1, 1, -1])
copras = pm.COPRAS()
pref = copras(matrix, weights, types)
initial_ranking = copras.rank(pref)
call_kwargs = {
"matrix": matrix,
"weights": weights,
"types": types
}
ranking_descending = True
direction = np.array([1, -1, 1])
step = 0.5
max_modification = 100
results = ranking.ranking_demotion(matrix, initial_ranking, copras, call_kwargs, ranking_descending, direction, step, max_modification=max_modification)
print('Initial ranking:')
display(Matrix(initial_ranking).T)
print(f'Example result (1/{len(results)}):\n')
print(f'Alternative index: {results[0][0]}')
print(f'Criterion index: {results[0][1]}')
print(f'Size of change: {results[0][2]}')
print(f'New position: {results[0][3]}')
Initial ranking:
Example result (1/9):
Alternative index: 0
Criterion index: 0
Size of change: 5.0
New position: 3
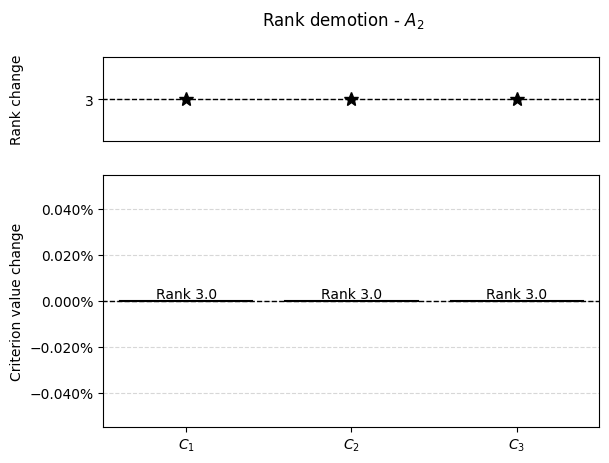
The results from demotion analysis can be further visualized
[5]:
results = np.array(results)
for alt in range(matrix.shape[1]):
alt_results = results[results[:, 0] == alt]
percentage_changes = []
new_positions = []
if len(alt_results):
for crit in range(matrix.shape[0]):
r = alt_results[alt_results[:, 1] == crit]
if len(r):
_ , crit, change, new_pos = r[0]
crit = int(crit)
if initial_ranking[alt] == new_pos:
percentage_changes.append(0)
else:
percentage_changes.append((change - matrix[alt, crit])/matrix[alt, crit]*100)
new_positions.append(new_pos)
else:
percentage_changes.append(0)
new_positions.append(initial_ranking[alt])
step = int(np.max(np.abs([np.min(np.array(percentage_changes))/5, np.max(np.array(percentage_changes))/5])))
graphs.pd_rankings_graph(initial_ranking[alt], new_positions, np.array(percentage_changes), kind='bar', title=f'Rank demotion - $A_{{{alt+1}}}$')
plt.show()

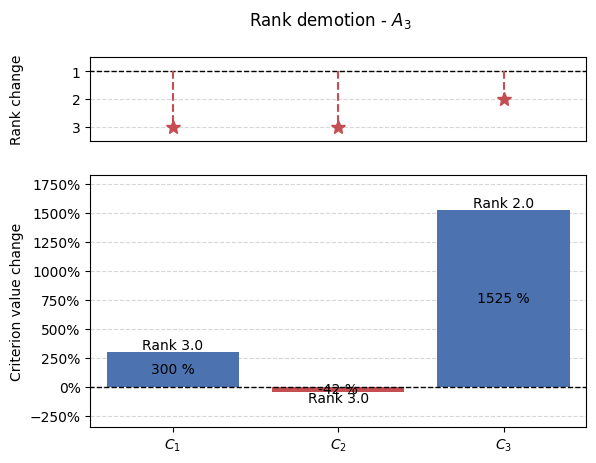
4.3. Promotion
[86]:
import pymcdm.methods as pm
matrix = np.array([
[4, 2, 6],
[7, 3, 2],
[9, 6, 8]
])
weights = np.array([0.4, 0.5, 0.1])
types = np.array([-1, 1, -1])
copras = pm.COPRAS()
pref = copras(matrix, weights, types)
initial_ranking = copras.rank(pref)
call_kwargs = {
"matrix": matrix,
"weights": weights,
"types": types
}
ranking_descending = True
direction = np.array([-1, 1, -1])
step = 0.5
max_modification = 1000
results = ranking.ranking_promotion(matrix, initial_ranking, copras, call_kwargs, ranking_descending, direction, step, max_modification=max_modification)
print('Initial ranking:')
display(Matrix(initial_ranking).T)
print(f'Example result (1/{len(results)}):\n')
print(f'Alternative index: {results[0][0]}')
print(f'Criterion index: {results[0][1]}')
print(f'Size of change: {results[0][2]}')
print(f'New position: {results[0][3]}')
Initial ranking:
Example result (1/9):
Alternative index: 0
Criterion index: 0
Size of change: 2.5
New position: 1
Results from the promotion function can be visualized similarly to demotion.
[87]:
results = np.array(results)
for alt in range(matrix.shape[1]):
alt_results = results[results[:, 0] == alt]
percentage_changes = []
new_positions = []
if len(alt_results):
for crit in range(matrix.shape[0]):
r = alt_results[alt_results[:, 1] == crit]
if len(r):
_ , crit, change, new_pos = r[0]
crit = int(crit)
if initial_ranking[alt] == new_pos:
percentage_changes.append(0)
else:
percentage_changes.append((change - matrix[alt, crit])/matrix[alt, crit]*100)
new_positions.append(new_pos)
else:
percentage_changes.append(0)
new_positions.append(initial_ranking[alt])
graphs.pd_rankings_graph(initial_ranking[alt], new_positions, np.array(percentage_changes), kind='bar', title=f'Rank promotion - $A_{{{alt+1}}}$')
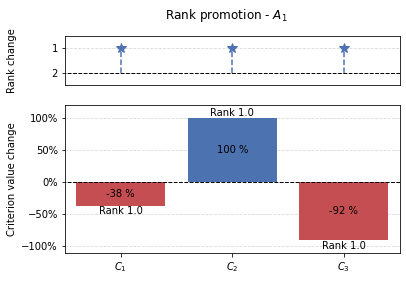


4.4. Fuzzy ranking
This function calculates fuzzy ranking from multiple acquired rankings. For example generate_weights_scenarios could be used to calculate multiple rankings and then fuzzy ranking could be calculated.
[8]:
rankings = np.array([
[1, 2, 3, 4, 5],
[2, 1, 5, 3, 4],
[4, 3, 2, 5, 1],
[3, 2, 1, 4, 5],
])
fuzzy_rank = ranking.fuzzy_ranking(rankings, normalization_axis=0)
print('Resulting fuzzy rank:')
display(Matrix(fuzzy_rank))
Resulting fuzzy rank:
This can be futher visualized using heatmap.
[9]:
graphs.heatmap(fuzzy_rank, title="Fuzzy Ranking Matrix", figsize=(8, 6))
plt.show()

5. Compromise submodule
This submodule consist of functions that calculate compromise between different rankings.
5.1. General
Most methods work in similar fashion, by either providing rankings or preferences we can calculate the compromised ranking.
Let us consider following ranking and preferences acquired using TOPSIS and VIKOR.
[90]:
preferences = np.array([[0.601, 0.5254],
[0.5355, 0.635],
[0.497, 0.7257],
[0.5648, 0.1143],
[0.5713, 0.5775],
[0.3163, 1.0],
[0.5559, 0.6188],
[0.6186, 0.2039]])
rankings = np.array([[2., 3.],
[6., 6.],
[7., 7.],
[4., 1.],
[3., 4.],
[8., 8.],
[5., 5.],
[1., 2.]])
print('Initial preferences:')
display(Matrix(preferences))
print('Initial rankings:')
display(Matrix(rankings))
Initial preferences:
Initial rankings:
Borda
[91]:
print('Resulting compromise ranking:')
display(Matrix(compromise.borda(rankings)).T)
Resulting compromise ranking:
Dominance directed graph
[92]:
print('Resulting compromise ranking:')
display(Matrix(compromise.dominance_directed_graph(rankings)).T)
Resulting compromise ranking:
Rank position method
[93]:
print('Resulting compromise ranking:')
display(Matrix(compromise.rank_position(rankings)).T)
Resulting compromise ranking:
Half-quadratic compromise
[94]:
print('Resulting compromise ranking:')
display(Matrix(compromise.HQ_compromise(rankings)[2]).T)
Resulting compromise ranking:
Improved borda
[95]:
print('Resulting compromise ranking:')
display(Matrix(compromise.improved_borda(preferences, [1, -1])).T)
Resulting compromise ranking:
5.2. HQ compromise additional informations
HQ compromise method apart from resulting in the compromised ranking it provides consensus index and trust index and weights of each ranking which can be of help to decision-maker.
5.3. ICRA
ICRA is presented separately as it provides more in-depth compromise seeking.
In this example the same initial preferences will be used
[96]:
import pymcdm.methods as pm
topsis = pm.TOPSIS()
vikor = pm.VIKOR()
methods = {
topsis: ['matrix', 'weights', 'types'],
vikor: ['matrix', 'weights', 'types']
}
ICRA_matrix = np.array([preferences[:, 0], preferences[:, 1]]).T
method_types = np.array([1, -1])
result = compromise.ICRA.iterative_compromise(methods, ICRA_matrix, method_types)
print('Resulting compromise ranking:')
display(Matrix(result.final_rankings[:, 0]).T)
Resulting compromise ranking:
In the case of ICRA, we can visualize the preference distribution change.
[97]:
graphs.ICRA_pref_distribution(result, ['TOPSIS', 'VIKOR'], by='methods')
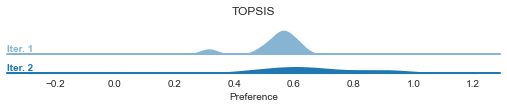
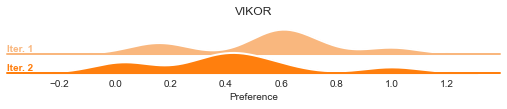
[98]:
graphs.ICRA_pref_distribution(result, ['TOPSIS', 'VIKOR'], by='iters')
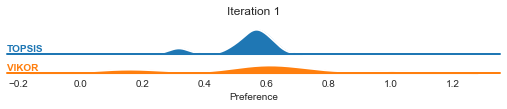
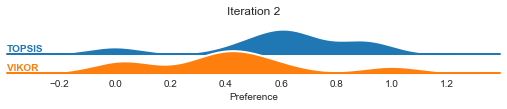
6. Further use
For most of the functions that modifies the decision matrix or weights vector, the library includes a wrapper for calculating the preference values and rankings for the returned results.
Example
[11]:
import pymcdm.methods as pm
weights = np.array([0.3, 0.3, 0.4])
percentage = 5
results = criteria.percentage_modification(weights, percentage)
topsis = pm.TOPSIS()
kwargs = {
'matrix': np.random.random((10, 3)),
'weights': weights,
'types': np.ones(3)
}
preferences_results = calculate_preference(criteria.percentage_modification, results, topsis, kwargs, only_preference=False, method_type=1)
preferences_results
[11]:
[(0,
-0.01,
array([0.297 , 0.3015, 0.4015]),
array([0.51678751, 0.55551396, 0.5424899 , 0.5327461 , 0.8729778 ,
0.60007671, 0.67895253, 0.53752998, 0.53180224, 0.41186704]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(0,
0.01,
array([0.303 , 0.2985, 0.3985]),
array([0.51256609, 0.55601744, 0.54160678, 0.53558126, 0.87405107,
0.60223144, 0.6732294 , 0.54053392, 0.53493021, 0.41050874]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(0,
-0.02,
array([0.294, 0.303, 0.403]),
array([0.51888048, 0.55526178, 0.54291742, 0.53135005, 0.87244873,
0.59901585, 0.68181741, 0.53605071, 0.5302561 , 0.41253727]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(0,
0.02,
array([0.306, 0.297, 0.397]),
array([0.51043834, 0.55626863, 0.54115115, 0.53701994, 0.87459513,
0.60332495, 0.6703714 , 0.54205815, 0.53651147, 0.40982076]),
array([ 9., 4., 6., 7., 1., 3., 2., 5., 8., 10.])),
(0,
-0.03,
array([0.291 , 0.3045, 0.4045]),
array([0.52096116, 0.55500938, 0.54333561, 0.52996862, 0.8719248 ,
0.59796622, 0.68468432, 0.53458686, 0.52872222, 0.41320148]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(0,
0.03,
array([0.309 , 0.2955, 0.3955]),
array([0.50829969, 0.55651939, 0.5406861 , 0.5384724 , 0.87514405,
0.604429 , 0.66751595, 0.54359693, 0.53810387, 0.40912695]),
array([ 9., 4., 6., 7., 1., 3., 2., 5., 8., 10.])),
(0,
-0.04,
array([0.288, 0.306, 0.406]),
array([0.52302918, 0.55475682, 0.54374449, 0.52860203, 0.87140606,
0.59692798, 0.68755312, 0.53313863, 0.5272009 , 0.41385966]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(0,
0.04,
array([0.312, 0.294, 0.394]),
array([0.50615049, 0.55676966, 0.54021165, 0.53993842, 0.87569774,
0.60554339, 0.66466316, 0.54515003, 0.53970713, 0.40842737]),
array([ 9., 4., 6., 7., 1., 3., 2., 5., 8., 10.])),
(0,
-0.05,
array([0.285 , 0.3075, 0.4075]),
array([0.5250842 , 0.55450413, 0.5441441 , 0.52725046, 0.8708926 ,
0.59590129, 0.69042368, 0.53170623, 0.52569239, 0.41451175]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(0,
0.05,
array([0.315 , 0.2925, 0.3925]),
array([0.50399107, 0.55701939, 0.53972777, 0.54141777, 0.87625614,
0.60666793, 0.66181317, 0.54671723, 0.54132094, 0.40772209]),
array([ 9., 4., 8., 6., 1., 3., 2., 5., 7., 10.])),
(1,
-0.01,
array([0.3015, 0.297 , 0.4015]),
array([0.51556696, 0.55853097, 0.54446919, 0.5327426 , 0.87390425,
0.60014958, 0.67504746, 0.5375275 , 0.53273897, 0.40811961]),
array([ 9., 4., 5., 7., 1., 3., 2., 6., 8., 10.])),
(1,
0.01,
array([0.2985, 0.303 , 0.3985]),
array([0.51378439, 0.55299821, 0.5396288 , 0.53558476, 0.87311802,
0.60215825, 0.67714169, 0.54053639, 0.53399011, 0.41425907]),
array([ 9., 4., 6., 7., 1., 3., 2., 5., 8., 10.])),
(1,
-0.02,
array([0.303, 0.294, 0.403]),
array([0.51643745, 0.56129323, 0.54687692, 0.53134305, 0.87429485,
0.59916126, 0.67401471, 0.53604574, 0.53212602, 0.40504552]),
array([ 9., 4., 5., 8., 1., 3., 2., 6., 7., 10.])),
(1,
0.02,
array([0.297, 0.306, 0.397]),
array([0.51287239, 0.55022834, 0.53719685, 0.53702693, 0.87272258,
0.60317829, 0.67820297, 0.54206309, 0.53462812, 0.41732409]),
array([ 9., 4., 6., 7., 1., 3., 2., 5., 8., 10.])),
(1,
-0.03,
array([0.3045, 0.291 , 0.4045]),
array([0.51729402, 0.5640523 , 0.54927585, 0.52995813, 0.87468365,
0.59818383, 0.67299165, 0.53457939, 0.53152158, 0.40196878]),
array([ 9., 4., 5., 8., 1., 3., 2., 6., 7., 10.])),
(1,
0.03,
array([0.2955, 0.309 , 0.3955]),
array([0.51194664, 0.54745654, 0.53475754, 0.53848288, 0.87232572,
0.60420856, 0.67927359, 0.54360433, 0.53527429, 0.42038576]),
array([ 9., 4., 8., 6., 1., 3., 2., 5., 7., 10.])),
(1,
-0.04,
array([0.306, 0.288, 0.406]),
array([0.51813664, 0.56680786, 0.55166559, 0.52858804, 0.87507057,
0.59721743, 0.67197837, 0.53312867, 0.53092575, 0.39888958]),
array([ 9., 4., 5., 8., 1., 3., 2., 6., 7., 10.])),
(1,
0.04,
array([0.294, 0.312, 0.394]),
array([0.51100721, 0.54468311, 0.53231121, 0.53995239, 0.87192752,
0.60524892, 0.68035342, 0.54515988, 0.53592852, 0.4234439 ]),
array([ 9., 5., 8., 6., 1., 3., 2., 4., 7., 10.])),
(1,
-0.05,
array([0.3075, 0.285 , 0.4075]),
array([0.51896528, 0.56955955, 0.55404576, 0.52723297, 0.8754555 ,
0.59626221, 0.67097494, 0.53169377, 0.5303386 , 0.39580811]),
array([ 9., 4., 5., 8., 1., 3., 2., 6., 7., 10.])),
(1,
0.05,
array([0.2925, 0.315 , 0.3925]),
array([0.51005415, 0.54190833, 0.5298582 , 0.54143523, 0.87152809,
0.60629917, 0.68144237, 0.54672951, 0.53659072, 0.42649838]),
array([ 9., 5., 8., 6., 1., 3., 2., 4., 7., 10.])),
(2,
-0.01,
array([0.302, 0.302, 0.396]),
array([0.5106747 , 0.55241392, 0.53823343, 0.53794661, 0.87370342,
0.60392907, 0.67367498, 0.54303827, 0.53628287, 0.41437611]),
array([ 9., 4., 6., 7., 1., 3., 2., 5., 8., 10.])),
(2,
0.01,
array([0.298, 0.298, 0.404]),
array([0.51868017, 0.55911958, 0.54586486, 0.53037675, 0.87332073,
0.59837791, 0.67851337, 0.53502099, 0.53044409, 0.40800134]),
array([ 9., 4., 5., 8., 1., 3., 2., 6., 7., 10.])),
(2,
-0.02,
array([0.304, 0.304, 0.392]),
array([0.50665658, 0.54906422, 0.53440628, 0.54174663, 0.87389508,
0.60671867, 0.67126939, 0.54706238, 0.53921099, 0.41755663]),
array([ 9., 4., 8., 6., 1., 3., 2., 5., 7., 10.])),
(2,
0.02,
array([0.296, 0.296, 0.408]),
array([0.52266735, 0.56247461, 0.54966872, 0.52660736, 0.87312986,
0.59561744, 0.68094514, 0.53102795, 0.52753462, 0.40480808]),
array([ 9., 4., 5., 8., 1., 3., 2., 6., 7., 10.])),
(2,
-0.03,
array([0.306, 0.306, 0.388]),
array([0.50262833, 0.54571726, 0.5305718 , 0.54555642, 0.87408686,
0.60951688, 0.66887358, 0.55109671, 0.54214412, 0.42073191]),
array([ 9., 5., 8., 6., 1., 3., 2., 4., 7., 10.])),
(2,
0.03,
array([0.294, 0.294, 0.412]),
array([0.52664406, 0.56583051, 0.55346439, 0.52284861, 0.87293942,
0.59286776, 0.68338461, 0.5270454 , 0.52463254, 0.40161152]),
array([ 7., 4., 5., 9., 1., 3., 2., 6., 8., 10.])),
(2,
-0.04,
array([0.308, 0.308, 0.384]),
array([0.49859005, 0.54237353, 0.52673025, 0.54937573, 0.87427867,
0.61232311, 0.66648806, 0.5551412 , 0.54508165, 0.4239014 ]),
array([ 9., 7., 8., 5., 1., 3., 2., 4., 6., 10.])),
(2,
0.04,
array([0.292, 0.292, 0.416]),
array([0.53061021, 0.56918682, 0.55725171, 0.51910073, 0.87274947,
0.5901294 , 0.68583128, 0.5230734 , 0.52173841, 0.39841214]),
array([ 6., 4., 5., 9., 1., 3., 2., 7., 8., 10.])),
(2,
-0.05,
array([0.31, 0.31, 0.38]),
array([0.49454185, 0.53903355, 0.52288187, 0.55320433, 0.87447042,
0.61513679, 0.66411339, 0.55919578, 0.54802294, 0.42706459]),
array([ 9., 7., 8., 5., 1., 3., 2., 4., 6., 10.])),
(2,
0.05,
array([0.29, 0.29, 0.42]),
array([0.53456575, 0.57254314, 0.56103047, 0.51536393, 0.8725601 ,
0.58740287, 0.68828464, 0.51911201, 0.51885281, 0.39521039]),
array([ 6., 4., 5., 9., 1., 3., 2., 7., 8., 10.]))]
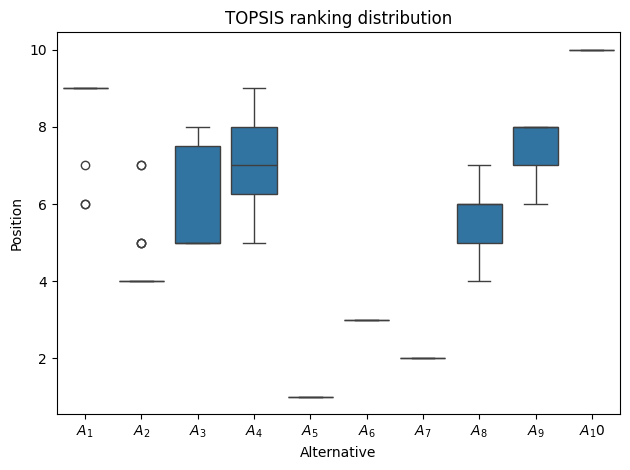
In the case of analyzing different criteria weights, we are left with multiple rankings, which for easier analysis can be further visualized.
[12]:
graphs.rankings_distribution(np.array([*np.array(preferences_results, dtype='object')[:, 4]]), title='TOPSIS ranking distribution')
plt.show()